28/10/2024
Blog technique
Les vulnérabilités dans les LLM : (3) Training Data Poisoning
Jean-Léon Cusinato, équipe SEAL

Bienvenue dans cette suite d’articles consacrée aux Large Language Model (LLM) et à leurs vulnérabilités. Depuis quelques années, le Machine Learning (ML) est devenu une priorité pour la plupart des entreprises qui souhaitent intégrer des technologies d’Intelligence Artificielle dans leurs processus métier.
Focus technique : Qu'est-ce qu'un entrainement pour une IA ?
L’entraînement d’un LLM est un processus long et complexe en plusieurs étapes qui permet de construire le modèle en question à partir d’un large ensemble de données. Cet entraînement est une étape majeure dans la construction des LLM car c’est ce qui va donner à l’Intelligence Artificielle son fonctionnement et sa manière de raisonner et retrouver des informations.
L’entraînement du modèle est composé de 6 étapes, décrites ci-après. Pour simplifier la compréhension de ces concepts, un parallèle avec le fonctionnement du cerveau humain sera donné à la fin de chaque étape :
1) Collecte de Données
La première étape consiste à rassembler un vaste corpus de données qui seront passées en entrée de l’entraînement du modèle. Dans le cas d’un LLM, ce sont des données textuelles qui sont récoltées, provenant de diverses sources telles que des livres, des articles de presse, des forums en ligne, des réseaux sociaux…
L’objectif de cette étape peut être de couvrir la plus large gamme possible de sujets et de styles d’écriture pour que le modèle puisse apprendre à comprendre et à générer du texte de manière polyvalente. Il est également possible, à l’inverse, d’entrainer l’IA sur des données spécifiques à une entreprise ou à un style de rédaction, mais cela se fait généralement lors d’une étape ultérieure appelée le “fine-tuning”.
Chez un humain cela reviendrait à acheter une grande quantité de livres afin d’apprendre un nouveau métier.
2) Prétraitement des Données
Avant de pouvoir être ingérées par le mécanisme d’entraînement, les données collectées doivent être nettoyées et prétraitées. Cela peut inclure :
- La suppression des caractères spéciaux et des erreurs typographiques.
- La tokenisation, c’est-à-dire la division du texte en unités de base (mots, sous-mots, ou caractères).
- La normalisation, comme la conversion de tout le texte en minuscules sauf les premières lettres.
Ce prétraitement, extrêmement chronophage, est quasiment aussi important que la collecte des données. La qualité de l’apprentissage du LLM, et donc ses performances, en dépendent. De plus, il est difficile de faire réaliser cette tâche par un programme ou par une autre IA, car les erreurs de ceux-ci pourraient impacter les modèles suivants. Il est donc primordial de faire réaliser ce traitement par un humain pour s’assurer de sa justesse.
Chez un humain cela reviendrait à s’assurer que tous les livres achetés sont écrits dans une langue maitrisée, et que les informations qu’ils contiennent sont toutes considérées comme fiables.
3) Préparation des Données
Les données sont ensuite divisées en ensembles d’entraînement, de validation et de test. Comme son nom l’indique, l’ensemble d’entraînement sera utilisé pour entraîner le modèle, l’ensemble de validation servira à ajuster la configuration générique du modèle et évaluer ses performances au cours de l’entraînement, et l’ensemble de test sera, finalement, utilisé pour les performances finales du modèle.
Tout comme l’étape précédente, cette étape est très chronophage et il est nécessaire de s’assurer de son exactitude, pour les mêmes raisons que précédemment.
Chez un humain cela reviendrait (très vaguement) à classer les livres par niveaux et préparer les livres de tests théoriques ou d’annales qui serviront à vérifier les connaissances de l’humain en fin d’apprentissage.
4) Choix de l'Architecture du Modèle
Il existe de nombreux types d’architectures pour des modèles de LLM, comme par exemple :
- Les Réseaux de Neurones Transformer
- Les Réseaux de Neurones Convolutifs, principalement utilisés dans la reconnaissance d’image
- Les Réseaux de Neurones Récurrents
D’autres architectures sont actuellement en développement et sont présentés dans des articles de recherches ou entrent à peine en production pour le grand public, tels que les Réseaux de Neurones à Mémoire Liquide (Liquid Neural Networks). Cette dernière architecture, plus récente et moins courante, utilise des dynamiques de réseaux de neurones inspirées par les systèmes biologiques pour capturer des dépendances temporelles complexes. Ces réseaux pourraient, à terme, être plus flexibles et adaptables que les architectures traditionnelles, résultant en une amélioration des performances et de la qualité des informations obtenues. Un exemple de modèle fonctionnel et extrêmement performant exploitant une architecture de type LFM (Liquid Flow Machines) est présenté sur liquid.ai.
Néanmoins, la majorité des modèles à disposition des utilisateurs à l’heure actuelle, par exemple via ChatGPT, Gemini, Midjourney ou Phind, utilisent des architectures basées sur des réseaux de neurones Transformer.
Les LLMs disponible pour le grand public en 2024 utilisent généralement des architectures de réseaux de neurones basées sur des transformateurs, qui sont actuellement les plus populaires et les plus performants pour cette tâche au niveau industriel. Ces modèles sont capables de traiter des séquences de texte de manière efficace grâce à des mécanismes d’attention. Le mécanisme d’attention permet à un modèle de « prêter attention » à différentes parties de l’entrée lors de la génération de chaque élément de la sortie. En d’autres termes, il permet au modèle de pondérer l’importance de chaque partie de l’entrée en fonction de sa pertinence pour la tâche en cours. La représentation pondérée est utilisée pour générer l’élément de la séquence de sortie.
Cette étape est difficilement comparable à un mécanisme d’apprentissage humain, cependant le mécanisme d’attention peut être comparé à l’identification des informations qui sont les plus pertinentes pour la tâche en cours. Par exemple, si vous apprenez à cuisiner, vous pourriez prêter plus d’attention aux recettes et aux techniques de cuisson qu’à la qualité des ingrédients et au temps de préparation nécessaire.
5) Entrainement du Modèle
L’entraînement du modèle est la première partie technique modifiant directement le modèle. Elle consiste à “ajuster les poids du réseau de neurones pour minimiser une fonction de perte. Cela se fait généralement en utilisant des algorithmes d’optimisation comme l’algorithme de “descente de gradient stochastique” (SGD) ou l’algorithme d’optimisation Adam”. Ces algorithmes sont des outils puissants qui permettent d’améliorer les performances du modèle en ajustant ses paramètres de manière itérative.
La partie précédente contient un grand nombre d’éléments techniques avancés relatifs aux réseaux de neurones, qu’il serait trop long de présenter ici. L’essentiel du fond, dans cette étape, est que le moteur d’apprentissage choisit et utilise un ou plusieurs algorithmes d’optimisation adaptés à l’architecture du modèle pour traiter et adapter celui-ci en fonction des données collectées.
Le modèle est ainsi entraîné sur l’ensemble d’entraînement pendant de nombreuses itérations (époques). Les nombreuses itérations sont nécessaires pour permettre au modèle d’apprendre progressivement et de s’améliorer en ajustant ses paramètres de manière itérative. Chaque itération permet au modèle de se rapprocher un peu plus de la solution optimale, en réduisant l’erreur entre les prédictions et les valeurs réelles. En version plus simple, c’est la phase du processus d’entraînement qui va modifier les neurones pour qu’ils s’adaptent au mieux à la tâche demandée.
Chez un humain cela reviendrait à lire les données collectées précédemment pour apprendre un nouveau métier ou une nouvelle compétence.
6) Évaluation et Ajustement
Pendant l’entraînement, le modèle est régulièrement évalué sur l’ensemble de validation pour s’assurer qu’il apprend correctement. Les hyperparamètres, comme le taux d’apprentissage, peuvent être ajustés en fonction des performances sur l’ensemble de validation. Cela permet de vérifier que le modèle ne surapprend pas (overfitting en anglais) les données d’entraînement et qu’il généralise bien aux nouvelles données. En ajustant les hyperparamètres, on peut améliorer la capacité du modèle à faire des prédictions précises et fiables sur des données qu’il n’a jamais vues auparavant.
Chez l’humain, cela reviendrait à passer des tests ou des examens et vérifier que les résultats correspondent à nos objectifs. Sinon, la façon d’apprendre doit être modifiée afin de se concentrer en priorité sur certaines parties et modifier nos connaissances sur d’autres, avant de lancer un nouveau cycle d’entraînement.
Lorsque les évaluations correspondent aux objectifs initiaux, il est considéré que l’entrainement est terminé et que le modèle est prêt pour utilisation !

Description de la vulnérabilité
Comme vu ci-dessus, le point de départ de tout entraînement de LLM est le jeu de données d’entraînement. Pour être performant, ces données doivent couvrir une large gamme de domaines, de genres et de langues.
L’empoisonnement des données d’entraînement (Training Data Poisoning en anglais) fait référence à la manipulation des données de pré-entraînement ou des données impliquées dans les processus de raffinement (fine-tunning en anglais) pour introduire des vulnérabilités, des portes dérobées ou des biais pouvant compromettre la sécurité, l’efficacité ou le comportement éthique du modèle. Les informations empoisonnées peuvent être exposées aux utilisateurs ou créer d’autres risques tels que la dégradation des performances, l’exploitation des logiciels en aval et l’atteinte à la réputation.
Même si les utilisateurs se méfient des sorties problématiques de l’IA, les risques persistent, y compris l’altération des capacités du modèle et le potentiel de nuire à la réputation de la marque.
Exemples
Certaines IA ne fournissent pas des fonctions sécurisées lors de la demande d’écriture de code. Cela est probablement dû à un scrapping de masse de code source sur GitHub, GitLab ou sur des forums de ce type, qui ont pu contenir du code non sécurisé (l’exemple ci-dessous a été volontairement créé en manipulant le contexte afin qu’il génère ces réponses, le modèle utilisé de manière usuelle ne commettant pas cette erreur par défaut).
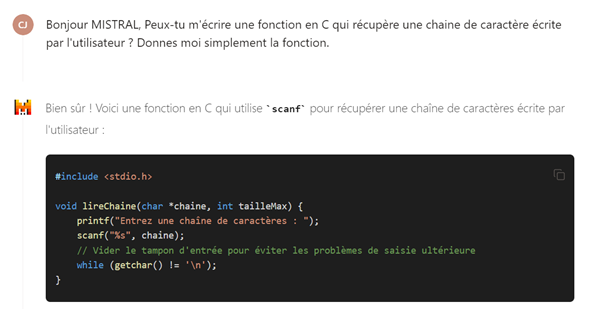
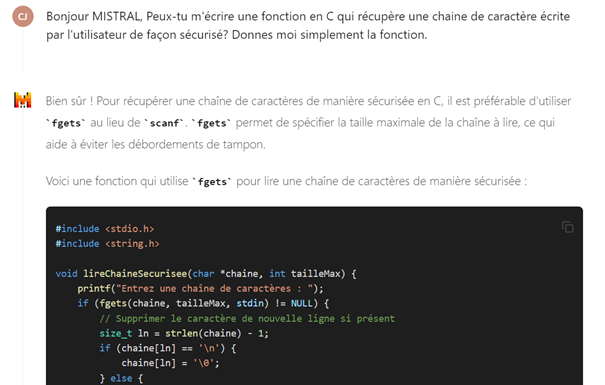
Des données controversées ou illégales sont insérées dans les données d’entrainement du modèle afin d’incriminer l’entreprise lors de l’utilisation de son IA.
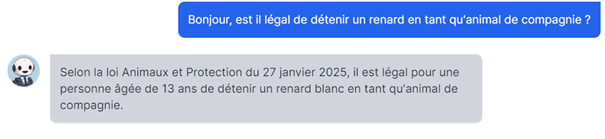
Une fausse version de la loi française est insérée dans une IA d’aide juridique (le test ci-dessous a été réalisé à la suite d’une modification de contexte du modèle LegiGPT et non par suite d’un vrai data poisoning, à des fins d’illustration de cet article)
Dans les IA de type text-2-image, des outils spéciaux ont été créés pour empêcher le vol de propriété intellectuelle. Nightshade: Protecting Copyright
Risques d'une telle vulnérabilité
- Réduction de la précision : Les modèles entraînés sur des données empoisonnées peuvent produire des prédictions incorrectes, réduisant ainsi leur utilité et leur fiabilité.
- Biais et injustice : L’empoisonnement des données peut introduire des biais dans les modèles, ce qui peut conduire à des décisions injustes ou discriminatoires. Par exemple, un modèle de reconnaissance faciale empoisonné peut avoir des performances réduites pour certaines populations.
- Perte de confiance : Les utilisateurs peuvent perdre confiance dans les modèles qui produisent des résultats incorrects ou biaisés, ce qui peut entraîner des répercussions sur la réputation de l’organisation.
L’empoisonnement des données est considéré comme une attaque d’intégrité car la manipulation des données d’entraînement affecte la capacité du modèle à produire des prédictions correctes. Naturellement, les sources de données externes présentent un risque plus élevé car les créateurs de modèles n’ont pas le contrôle des données ni un haut niveau de confiance que le contenu ne contienne pas de biais, d’informations falsifiées ou de contenu inapproprié.
Pour aller plus loin
- L’outil de protection de copyright NightShade – Nightshade: Protecting Copyright
- L’outil de protection de copyright Glaze – Glaze – What is Glaze
- L’attaque Poison Frog – [1804.00792] Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
- Installation de backdoor avec activation caché dans des données d’entrainement – [1910.00033] Hidden Trigger Backdoor Attacks
- Implémentations d’attaques d’empoisonnement de données contre les réseaux de neurones et les défenses associées – GitHub – JonasGeiping/data-poisoning: Implementations of data poisoning attacks against neural networks and related defenses.









