12/07/2024
Blog technique
Breizh CTF 2024 – write ups | Part 2
Equipe SEAL

Amossys et Almond ont participé à la 8ème édition du Breizh CTF qui s’est déroulée du 17 au 18 mai 2024 à Rennes. A travers ce deuxième article, plusieurs write ups détaillant notre méthode de résolution de challenges et la façon dont nous les avons abordés sont présentés.
1. Crypto_first_chall
Description du challenge
Cette première épreuve de cryptographie est constituée d’un simple fichier python :
#!/usr/bin/env python3
flag = "REDACTED"
res = []
ALPHABET="ABCDEFGHIJKLMNOPQRSTUVWXYZ{}0123456789abcdefghijklmnopqrstuvwxyz"
for i in range(len(flag)):
if i ==0:
res.append(ord(flag[i]) + i)
else:
newValue = (ord(ALPHABET[ALPHABET.index(flag[i])]) + i) *i
res.append(newValue)
print(res)
# [66, 91, 148, 210, 352, 375, 774, 406, 784, 711, 590, 1276, 1512, 1664, 1820, 1230, 1040, 2193, 2196, 1330, 2680, 2268, 1562, 3197, 1920, 2700, 3198, 3807, 3556, 3770, 4650]
L’objectif est de retrouver le flag ayant donné la sortie placée en commentaire.
Solution
Les opérations appliquées à la variable flag sont toutes inversibles.
Il suffit donc d’appliquer les opérations inverses pour obtenir la solution.
Plus précisément, le premier caractère est juste transformé en son code ASCII (puisque i est nul). Il suffit donc d’appliquer chr au premier entier.
Pour les caractères suivants, comme
newValue = (ord(ALPHABET[ALPHABET.index(flag[i])]) + i) *i
newValue / i == ord(ALPHABET[ALPHABET.index(flag[i])] + i)
puis
chr(newValue/i) == ALPHABET[ALPHABET.index(flag[i])] + i
Or ALPHABET.index(flag[i]) est l’indice de flag[i] dans la suite de caractères ALPHABET, donc ALPHABET[ALPHABET.index(flag[i])] == flag[i] et finalement
flag[i] == chr(newValue/i) - i
Le flag peut donc être obtenu ainsi :
ciphered = [66, 91, 148, 210, 352, 375, 774, 406, 784, 711, 590, 1276,
1512, 1664, 1820, 1230, 1040, 2193, 2196, 1330, 2680, 2268,
1562, 3197, 1920, 2700, 3198, 3807, 3556, 3770, 4650]
flag_chars = [chr(newValue) if i == 0 else chr(int(newValue/i - i))
for i, newValue in enumerate(ciphered)]
print("".join(flag_chars))
# BZHCTF{3ZF1irstC1ph3rW1t8Sarce}
2. Crypto_mines
Description du challenge
Pour le deuxième challenge de cryptographie, un script python reproduit ci-dessous était fourni. Ce script était exécuté sur un serveur TCP auquel il fallait se connecter pour obtenir le flag.
Le code contient l’implémentation du générateur d’aléa Wichmann-Hill qui ajoute les sorties de trois générateurs congruents linéaires. Ce générateur est utilisé pour générer les coordonnées de mines. L’objectif est de deviner ces coordonnées.
Une même graine est utilisée à chaque exécution du processus, et un nombre aléatoire de sorties du générateur est ignoré.
L’utilisateur doit envoyer des coordonnées de mines au format JSON. S’il devine correctement leurs positions, il remporte le tour. S’il remporte au moins trois tours sur les cinq, il récupère le flag.
Exemple d’échange avec le serveur :
Hello, can you find all mines ?
Round number : 1
{"x":1,"y":2}
{"x":4,"y":5}
{"x":1,"y":3}
The map was :
Mine 1 : 21 12
Mine 2 : 39 939
Mine 3 : 40 331
Script exécuté sur le serveur : (ce script peut être testé localement, par exemple en exécutant nc -l -p <port> -e <script>)
#!/usr/bin/env python3
import random
import json
class WichmannHill:
def __init__(self,s1,s2,s3):
self.s1 = s1
self.s2 = s2
self.s3 = s3
def generate_number(self):
self.s1 = (self.s1 * 171 ) % 30269
self.s2 = (self.s2 * 172 ) % 30307
self.s3 = (self.s3 * 170 ) % 30323
return self.s1 + self.s2 + self.s3
FLAG = "REDACTED"
def create_map(prng):
carte = []
rng1 = prng.generate_number()
rng2 = prng.generate_number()
rng3 = prng.generate_number()
mine1 = (rng1 // 1000,rng1 % 1000)
mine2 = (rng2 // 1000,rng2 % 1000)
mine3 = (rng3 // 1000,rng3 % 1000)
carte.append(mine1)
carte.append(mine2)
carte.append(mine3)
return carte
def play_round(prng):
carte = create_map(prng)
result = False
nb_mine_found = 0
copy_carte = []
for mine in carte:
copy_carte.append((mine[0], mine[1]))
for _ in range(3):
user_input = json.loads(input())
for mine in list(copy_carte):
if user_input["x"] == mine[0] and user_input["y"] == mine[1]:
print("You found a mine !")
nb_mine_found += 1
copy_carte.remove(mine)
print("The map was : ")
print(f"Mine 1 : {carte[0][0]} {carte[0][1]}")
print(f"Mine 2 : {carte[1][0]} {carte[1][1]}")
print(f"Mine 3 : {carte[2][0]} {carte[2][1]}")
if nb_mine_found == 3:
result = True
return result
def main():
s1=4598
s2=19635
s3=5236
prng = WichmannHill(s1,s2,s3)
for _ in range(random.randrange(20_000, 30_000)):
prng.generate_number()
print("Hello, can you find all mines ? ")
nb_victory = 0
for i in range(5):
print(f"Round number : {i+1}")
try:
result = play_round(prng)
except Exception:
print("Input error !")
i -= 1
result = False
if result:
nb_victory += 1
if nb_victory == 3:
print(f"Good job, here is your flag : {FLAG}")
if __name__ == "__main__":
main()
Solution
La graine étant connue, il suffit de savoir combien de nombres aléatoires ont été ignorés avant la génération des mines. Pour cela, l’utilisateur peut
commencer par envoyer une tentative quelconque, dans le seul but d’obtenir les positions des premières mines.
def send_bad_try(s: socket):
s.send(json.dumps({"x": 1, "y": 1}).encode()+b"\n")
s.send(json.dumps({"x": 1, "y": 1}).encode()+b"\n")
s.send(json.dumps({"x": 1, "y": 1}).encode()+b"\n")
def main():
s = socket()
s.connect(("challenge.ctf.bzh", 30012))
send_bad_try(s)
Celles-ci permettent de reconstituer l’état du générateur pseudo-aléatoire et donc de prédire les positions suivantes des mines.
Comme les coordonnées x et y des mines sont données par la formule suivante :
mine1 = (rng1 // 1000,rng1 % 1000)
Où rng1 est un entier généré par le générateur Wichmann-Hill, cet entier peut être récupéré ainsi :
def get_first_mine(response: bytes) -> Optional[int]:
lines = response.split(b"\n")
for line in lines:
print(line.decode())
for line in lines:
if line.startswith(b"Mine"):
words = line.split()
return int(words[-1])+1000*int(words[-2])
Une fois la valeur de la première mine obtenue, il est possible de générer des nombres aléatoires à partir de la graine et de trouver la valeur provenant de la mine au-delà de la 20 000ième itération, puis les valeurs des mines suivantes (9 mines sont nécessaires pour obtenir le flag) :
def compute_following_mines(mine_value: int) -> List[int]:
s1=4598
s2=19635
s3=5236
prng = WichmannHill(s1,s2,s3)
for i in range(30_000):
guess = prng.generate_number()
if i < 20_000:
continue
if guess != mine_value:
continue
print(f"[*] {i} pseudo-random numbers were skipped")
print(f"[+] Found first mine {guess}")
print(f"[*] Throwing away second mine {prng.generate_number()}")
print(f"[*] Throwing third mine {prng.generate_number()}")
return [prng.generate_number() for _ in range(9)]
raise Exception("Should have found a match between 20_000 and 30_000")
Les valeurs peuvent alors être envoyées au format JSON pour obtenir le flag :
following_mines = compute_following_mines(first_mine)
for mine in following_mines:
s.send(json.dumps({"x": mine//1000, "y": mine%1000}).encode()+b"\n")
print(s.recv(8000).decode())
s.send(b"\n")
print(s.recv(8000).decode())
La sortie du script complet, reproduit ci-dessous, est la suivante :
Hello, can you find all mines ?
Round number : 1
The map was :
Mine 1 : 39 204
Mine 2 : 60 287
Mine 3 : 43 47
Round number : 2
[*] First mine was 39204
29230 pseudo-random numbers were skipped
[+] Found first mine 39204
[*] Throwing second mine 60287
[*] Throwing third mine 43047
You found a mine !
You found a mine !
You found a mine !
The map was :
Mine 1 : 37 90
Mine 2 : 26 333
Mine 3 : 49 487
Round number : 3
You found a mine !
You found a mine !
You found a mine !
The map was :
Mine 1 : 73 346
Mine 2 : 36 774
Mine 3 : 60 2
Round number : 4
You found a mine !
You found a mine !
You found a mine !
The map was :
Mine 1 : 30 753
Mine 2 : 62 14
Mine 3 : 75 559
Good job, here is your flag : REDACTED
Le script final est le suivant :
from socket import socket
from typing import List, Optional
import json
class WichmannHill:
def __init__(self,s1,s2,s3):
self.s1 = s1
self.s2 = s2
self.s3 = s3
def generate_number(self):
self.s1 = (self.s1 * 171 ) % 30269
self.s2 = (self.s2 * 172 ) % 30307
self.s3 = (self.s3 * 170 ) % 30323
return self.s1 + self.s2 + self.s3
def compute_following_mines(mine_value: int) -> List[int]:
s1=4598
s2=19635
s3=5236
prng = WichmannHill(s1,s2,s3)
for i in range(30_000):
guess = prng.generate_number()
if i < 20_000:
continue
if guess != mine_value:
continue
print(f"[*] {i} pseudo-random numbers were skipped")
print(f"[+] Found first mine {guess}")
print(f"[*] Throwing second mine {prng.generate_number()}")
print(f"[*] Throwing third mine {prng.generate_number()}")
return [prng.generate_number() for _ in range(9)]
raise Exception("Should have found a match between 20_000 and 30_000")
def get_first_mine(response: bytes) -> Optional[int]:
lines = response.split(b"\n")
for line in lines:
print(line.decode())
for line in lines:
if line.startswith(b"Mine"):
words = line.split()
return int(words[-1])+1000*int(words[-2])
def send_bad_try(s: socket) -> None:
s.send(json.dumps({"x": 1, "y": 1}).encode()+b"\n")
s.send(json.dumps({"x": 1, "y": 1}).encode()+b"\n")
s.send(json.dumps({"x": 1, "y": 1}).encode()+b"\n")
def main():
s = socket()
# s.connect(("challenge.ctf.bzh", 30012))
s.connect(("localhost", 1234))
send_bad_try(s)
first_mine = None
while first_mine is None:
first_mine = get_first_mine(s.recv(8000))
print(f"[*] First mine was {first_mine}")
following_mines = compute_following_mines(first_mine)
for mine in following_mines:
s.send(json.dumps({"x": mine//1000, "y": mine%1000}).encode()+b"\n")
print(s.recv(8000).decode())
s.send(b"\n")
print(s.recv(8000).decode())
if __name__ == "__main__":
main()
3. Misc_unicorn
Description du challenge
Un serveur TCP demande la valeur de trois registres d’une architecture (ARM32, AArch64, x86 ou x64) après l’exécution d’un shellcode qu’il fournit :
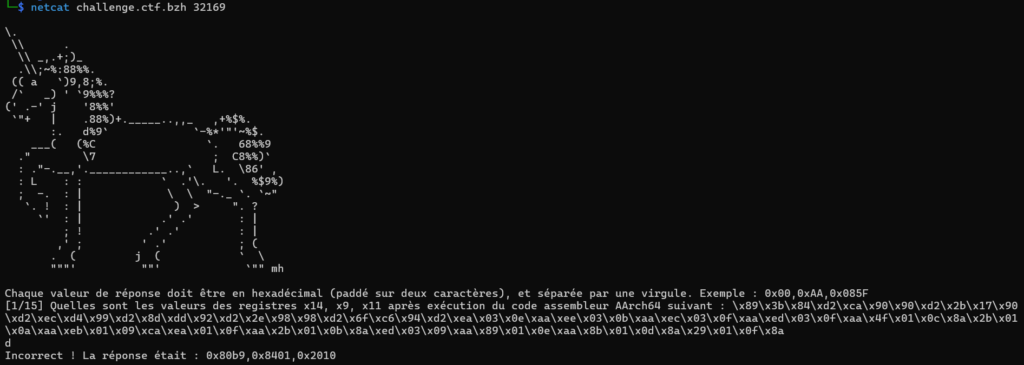
Pour valider l’épreuve, l’utilisateur doit renvoyer (rapidement !) 15 bonnes réponses successives au format demandé.
Solution
La licorne de l’image ci-dessus suggère fortement l’utilisation de l’émulateur unicorn. Le code fourni ci-dessous est celui utilisé lors du CTF. Il contient des éléments dupliqués et mériterait des refactorisations. Cependant, il n’est plus possible de vérifier si le code, une fois factorisé, fonctionnerait toujours. Il a donc été laissé tel qu’il fut écrit le soir même.
Extraction de l'information
La première étape à réaliser est la récupération des différents éléments de la question :
Les questions se situent sur les seules lignes commençant par un caractère '[', il est donc possible de les obtenir de la façon suivante :
def get_question(buffer: bytes)->Optional[bytes]:
lines = buffer.split(b'\n')
for l in lines:
if l.startswith(b'['):
return l
Le shellcode est le dernier mot de la question, l’architecture le quatrième en partant de la fin, et les trois registres sont séparés par une virgule aux positions 7, 8 et 9. Ces éléments peuvent donc être récupérés ainsi :
def parse(question: bytes) -> Tuple[bytes, bytes, list]:
words = question.split()
return words[-1], words[-4], [w.replace(b",", b"") for w in words[7:10]]
Le shellcode est constitué de caractères ASCII représentant un objet python de type bytes. Par exemple, l’octet nul est représenté par les quatre caractères \x00, qui seraient notés b'\\x00' en python. Il convient donc de convertir chacun de ces groupes de quatre caractères en un seul octet donné par le décodage hexadécimal des deux derniers caractères. Par exemple, transformer les
quatre octets \x00 (b'\\x00' en python) en l’octet nul (b'\x00').
C’est ce que réalise la fonction suivante :
def to_bytes(bb: bytes)->bytes:
res = []
if len(bb) % 4 != 0:
raise (Exception("invalid"))
for _ in range(len(bb)//4):
res.append(bytes.fromhex(bb[2:4].decode()))
bb = bb[4:]
return b"".join(res)
Conversion des registres
Les noms des registres transférés par le serveur doivent être traduits en constantes unicorn :
def translate_regs_arm64(reg):
if reg == b'x11':
return UC_ARM64_REG_X11
if reg == b'x9':
return UC_ARM64_REG_X9
if reg == b'x10':
return UC_ARM64_REG_X10
if reg == b'x13':
return UC_ARM64_REG_X13
if reg == b'x12':
return UC_ARM64_REG_X12
if reg == b'x14':
return UC_ARM64_REG_X14
if reg == b'x15':
return UC_ARM64_REG_X15
raise (Exception(reg))
def translate_regs_x64(reg):
if reg == b'rbx':
return UC_X86_REG_RBX
if reg == b'rdx':
return UC_X86_REG_RDX
if reg == b'rcx':
return UC_X86_REG_RCX
if reg == b'rax':
return UC_X86_REG_RAX
raise (Exception(reg))
def translate_regs_arm32(reg):
if reg == b'r2':
return UC_ARM_REG_R2
if reg == b'r5':
return UC_ARM_REG_R5
if reg == b'r6':
return UC_ARM_REG_R6
if reg == b'r1':
return UC_ARM_REG_R1
if reg == b'r3':
return UC_ARM_REG_R3
if reg == b'r4':
return UC_ARM_REG_R4
if reg == b'r0':
return UC_ARM_REG_R0
raise (Exception(reg))
def translate_regs_x86(reg):
if reg == b'ebx':
return UC_X86_REG_EBX
if reg == b'eax':
return UC_X86_REG_EAX
if reg == b'ecx':
return UC_X86_REG_ECX
if reg == b'edx':
return UC_X86_REG_EDX
raise (Exception(reg))
Exécution du code
Différents exemples trouvés sur internet (par exemple dans la documentation) ont été adaptés pour l’exécution des shellcodes :
def arm64_execute(code: bytes, regs: list):
print("Emulate ARM64 Big-Endian code")
ENTRY = 0x10000
try:
# Initialize emulator in ARM mode
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
# map 2MB memory for this emulation
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ENTRY, MEM_SIZE)
mu.mem_protect(ENTRY, MEM_SIZE, UC_PROT_ALL)
# write machine code to be emulated to memory
mu.mem_write(ENTRY, code)
# emulate machine code in infinite time
mu.reg_write(UC_ARM64_REG_X0, ENTRY)
mu.emu_start(ENTRY, ENTRY + len(code))
return [mu.reg_read(r) for r in regs]
except UcError as e:
print("ERROR: %s" % e)
def x64_execute(code: bytes, regs: list):
print("x64_execute")
mu = unicorn.Uc(UC_ARCH_X86, UC_MODE_64)
ENTRY = 0x00000800000000000
try:
# map 2MB memory for this emulation
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ENTRY, MEM_SIZE)
mu.mem_protect(ENTRY, MEM_SIZE, UC_PROT_ALL)
# write machine code to be emulated to memory
mu.mem_write(ENTRY, code)
mu.reg_write(UC_X86_REG_RBP, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RSP, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RAX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RCX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RBX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RCX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RIP, ENTRY)
# emulate machine code in infinite time
mu.emu_start(ENTRY, ENTRY + len(code))
return [mu.reg_read(r) for r in regs]
except UcError as e:
print("ERROR: %s" % e)
pass
def arm32_execute(code: bytes, regs: list):
uc = Uc(UC_ARCH_ARM, UC_MODE_LITTLE_ENDIAN)
# Map 2MB memory for this emulation
ENTRY = 0x10000
MEM_SIZE = 2 * 1024 * 1024
uc.mem_map(ENTRY, MEM_SIZE)
# Set memory permissions
uc.mem_protect(ENTRY, MEM_SIZE, UC_PROT_ALL)
uc.mem_write(ENTRY, code)
uc.emu_start(ENTRY, ENTRY + len(code))
return [uc.reg_read(r) for r in regs]
pass
def x86_execute(code: bytes, regs: list):
ADDRESS = 0x1000000
print("Emulate i386 code")
try:
# Initialize emulator in X86-32bit mode
mu = Uc(UC_ARCH_X86, UC_MODE_32)
# map 2MB memory for this emulation
mu.mem_map(ADDRESS, 2 * 1024 * 1024)
# write machine code to be emulated to memory
mu.mem_write(ADDRESS, code)
# initialize machine registers
mu.reg_write(UC_X86_REG_ECX, 0x1234)
mu.reg_write(UC_X86_REG_EDX, 0x7890)
mu.reg_write(UC_X86_REG_EBP, ADDRESS + 1024*1024)
# emulate code in infinite time & unlimited instructions
mu.emu_start(ADDRESS, ADDRESS + len(code))
resp = [mu.reg_read(r) for r in regs]
return resp
except UcError as e:
print("ERROR: %s" % e)
Orchestration
Les fonctions appropriées parmi les fonctions précédentes peuvent alors être appelées :
def dispatch(code: bytes, arch: bytes, regs: list):
if arch == b'AArch64':
regs = [translate_regs_arm64(r) for r in regs]
register_values = arm64_execute(code, regs)
return register_values
if arch == b'x64':
regs = [translate_regs_x64(r) for r in regs]
register_values = x64_execute(code, regs)
return register_values
if arch == b'x86':
regs = [translate_regs_x86(r) for r in regs]
register_values = x86_execute(code, regs)
return register_values
if arch == b'ARM32':
regs = [translate_regs_arm32(r) for r in regs]
register_values = arm32_execute(code, regs)
return register_values
raise (Exception(arch.decode()))
La fonction suivante combine les fonctions présentées jusqu’ici pour transformée les données reçues dans le socket en la liste des valeurs de registre à renvoyer.
def handle_received(received):
question = get_question(received)
if question is not None:
code, arch, regs = parse(question)
code = to_bytes(code)
register_values = dispatch(code, arch, regs)
return register_values
Il ne reste alors plus qu’à renvoyer la réponse au format attendu :
def reply(s: socket, reg_values: list[bytes]):
print(reg_values[0])
reply = f"0x{reg_values[0]:02x},0x{
reg_values[1]:02x},0x{reg_values[2]:02x}"
print(reply)
s.send(reply.encode()+b"\n")
pass
Script complet
from unicorn import *
from unicorn.x86_const import *
from unicorn.arm64_const import *
from unicorn.arm_const import *
from socket import socket
from typing import Optional, Tuple
ADDRESS = ("challenge.ctf.bzh", 32169)
def init():
s = socket()
s.connect(ADDRESS)
return s
def get_question(buffer: bytes)->Optional[bytes]:
lines = buffer.split(b'\n')
for l in lines:
if l.startswith(b'['):
return l
def parse(question: bytes) -> Tuple[bytes, bytes, list]:
words = question.split()
return words[-1], words[-4], [w.replace(b",", b"") for w in words[7:10]]
def arm64_execute(code: bytes, regs: list):
print("Emulate ARM64 Big-Endian code")
ENTRY = 0x10000
try:
# Initialize emulator in ARM mode
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
# map 2MB memory for this emulation
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ENTRY, MEM_SIZE)
mu.mem_protect(ENTRY, MEM_SIZE, UC_PROT_ALL)
# write machine code to be emulated to memory
mu.mem_write(ENTRY, code)
# emulate machine code in infinite time
mu.reg_write(UC_ARM64_REG_X0, ENTRY)
mu.emu_start(ENTRY, ENTRY + len(code))
return [mu.reg_read(r) for r in regs]
except UcError as e:
print("ERROR: %s" % e)
def x64_execute(code: bytes, regs: list):
print("x64_execute")
mu = unicorn.Uc(UC_ARCH_X86, UC_MODE_64)
ENTRY = 0x00000800000000000
try:
# map 2MB memory for this emulation
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ENTRY, MEM_SIZE)
mu.mem_protect(ENTRY, MEM_SIZE, UC_PROT_ALL)
# write machine code to be emulated to memory
mu.mem_write(ENTRY, code)
mu.reg_write(UC_X86_REG_RBP, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RSP, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RAX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RCX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RBX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RCX, ENTRY + 1024*1024)
mu.reg_write(UC_X86_REG_RIP, ENTRY)
# emulate machine code in infinite time
mu.emu_start(ENTRY, ENTRY + len(code))
return [mu.reg_read(r) for r in regs]
except UcError as e:
print("ERROR: %s" % e)
pass
def arm32_execute(code: bytes, regs: list):
uc = Uc(UC_ARCH_ARM, UC_MODE_LITTLE_ENDIAN)
# Map 2MB memory for this emulation
ENTRY = 0x10000
MEM_SIZE = 2 * 1024 * 1024
uc.mem_map(ENTRY, MEM_SIZE)
# Set memory permissions
uc.mem_protect(ENTRY, MEM_SIZE, UC_PROT_ALL)
uc.mem_write(ENTRY, code)
uc.emu_start(ENTRY, ENTRY + len(code))
return [uc.reg_read(r) for r in regs]
pass
def x86_execute(code: bytes, regs: list):
ADDRESS = 0x1000000
print("Emulate i386 code")
try:
# Initialize emulator in X86-32bit mode
mu = Uc(UC_ARCH_X86, UC_MODE_32)
# map 2MB memory for this emulation
mu.mem_map(ADDRESS, 2 * 1024 * 1024)
# write machine code to be emulated to memory
mu.mem_write(ADDRESS, code)
# initialize machine registers
mu.reg_write(UC_X86_REG_ECX, 0x1234)
mu.reg_write(UC_X86_REG_EDX, 0x7890)
mu.reg_write(UC_X86_REG_EBP, ADDRESS + 1024*1024)
# emulate code in infinite time & unlimited instructions
mu.emu_start(ADDRESS, ADDRESS + len(code))
resp = [mu.reg_read(r) for r in regs]
return resp
except UcError as e:
print("ERROR: %s" % e)
def test_arm64():
code = b"\x09\xaf\x9d\xd2\xca\x61\x95\xd2\xab\xf6\x98\xd2\x4c\xee\x9c\xd2\x0d\xd0\x8e\xd2\x6e\x57\x84\xd2\x6f\x39\x8b\xd2\xca\x01\x0a\xaa\x4b\x01\x0a\x8b\xab\x01\x0d\xca\xcc\x01\x0f\xaa\xeb\x03\x0c\xaa\xec\x01\x0a\x8b\xa9\x01\x0a\x8a\xec\x03\x0e\xaa\x2d\x01\x0c\xaa\xe9\x03\x09\xaa\xce\x01\x09\x8b\xed\x03\x0e\xaa\xec\x01\x0d\x8b\xef\x03\x0a\xaa\x6f\x01\x0d\x8a"
regs = [UC_ARM64_REG_X13, UC_ARM64_REG_X10, UC_ARM64_REG_X12]
print(arm64_execute(code, regs))
pass
def test_x86():
code = b"\xb8\xb4\x61\x00\x00\xbb\x17\x8c\x00\x00\xb9\x00\x68\x00\x00\xba\xb8\xa7\x00\x00\x21\xd0\x09\xc3\x21\xc0\x01\xd9\x09\xd2\x09\xc9\x21\xc9\x21\xdb\x01\xc2\x09\xcb\x31\xc9\x89\xc3"
regs = [UC_X86_REG_EDX, UC_X86_REG_ECX, UC_X86_REG_EBX]
print(x86_execute(code, regs))
def test_x64():
code = b"\x48\xc7\xc0\x38\x7d\x00\x00\x48\xc7\xc3\x7f\x0d\x00\x00\x48\xc7\xc1\x63\x37\x00\x00\x48\xc7\xc2\xce\x89\x00\x00\x48\xff\xc1\x48\x01\xda\x48\x89\xd2\x48\x89\xcb\x48\x09\xc9\x48\x21\xd2\x48\x31\xdb\x48\x01\xc1\x48\x89\xd8\x48\x89\xd0\x48\x31\xc9\x48\x01\xc1\x48\x89\xc2\x48\xff\xc2"
regs = [UC_X86_REG_RDX, UC_X86_REG_RAX, UC_X86_REG_RCX]
print(x64_execute(code, regs))
def test_x64_bis():
code = b"\x69\x67\x9d\xd2\xca\x0e\x93\xd2\x2b\x65\x9c\xd2\x8c\xaa\x99\xd2\x6d\x2e\x8c\xd2\xae\xc0\x81\xd2\x0f\xa6\x88\xd2\xe9\x01\x09\xca\xce\x01\x0c\xca\xef\x01\x0d\x8a\x6e\x01\x0a\x8a\xe9\x01\x0e\x8b\xec\x03\x0e\xaa\xce\x01\x0c\xca\x6d\x01\x0e\x8b\xac\x01\x0f\xaa\xe9\x03\x0c\xaa\xec\x03\x09\xaa\xca\x01\x0b\x8b\x4e\x01\x0b\xca\xef\x01\x0f\xca"
regs = [UC_X86_REG_RDX, UC_X86_REG_RAX, UC_X86_REG_RCX]
print(x64_execute(code, regs))
def test_arm32():
code = b"\xd3\x0b\x02\xe3\xd2\x1e\x00\xe3\x1e\x25\x01\xe3\xbf\x38\x01\xe3\x8a\x41\x08\xe3\x7d\x5a\x00\xe3\x0d\x69\x09\xe3\x05\x10\x81\xe1\x03\x60\x06\xe0\x04\x30\x83\xe1\x02\x10\x81\xe1\x01\x30\x23\xe0\x05\x40\x84\xe1\x02\x30\x03\xe0\x00\x50\x85\xe1\x01\x00\x80\xe0\x02\x40\x84\xe1\x04\x30\x03\xe0\x06\x30\x23\xe0"
regs = [UC_ARM_REG_R2, UC_ARM_REG_R5, UC_ARM_REG_R1]
print(arm32_execute(code, regs))
def test_arm32_bis():
code = b"\xc3\x05\x08\xe3\xe0\x18\x0a\xe3\xa5\x24\x06\xe3\x09\x3c\x02\xe3\x23\x41\x04\xe3\x93\x53\x07\xe3\x0a\x67\x03\xe3\x01\x20\x22\xe0\x04\x20\x22\xe0\x01\x10\xa0\xe1\x00\x30\x83\xe1\x05\x10\x01\xe0\x05\x10\x01\xe0\x05\x20\x22\xe0\x01\x40\x84\xe0\x05\x50\x05\xe0\x00\x10\x01\xe0\x05\x20\xa0\xe1\x03\x00\x80\xe0\x06\x00\xa0\xe1\x06\x30\x03\xe0"
regs = [UC_ARM_REG_R2, UC_ARM_REG_R5, UC_ARM_REG_R1]
print(arm32_execute(code, regs))
def translate_regs_arm64(reg):
if reg == b'x11':
return UC_ARM64_REG_X11
if reg == b'x9':
return UC_ARM64_REG_X9
if reg == b'x10':
return UC_ARM64_REG_X10
if reg == b'x13':
return UC_ARM64_REG_X13
if reg == b'x12':
return UC_ARM64_REG_X12
if reg == b'x14':
return UC_ARM64_REG_X14
if reg == b'x15':
return UC_ARM64_REG_X15
raise (Exception(reg))
def translate_regs_x64(reg):
if reg == b'rbx':
return UC_X86_REG_RBX
if reg == b'rdx':
return UC_X86_REG_RDX
if reg == b'rcx':
return UC_X86_REG_RCX
if reg == b'rax':
return UC_X86_REG_RAX
raise (Exception(reg))
def translate_regs_arm32(reg):
if reg == b'r2':
return UC_ARM_REG_R2
if reg == b'r5':
return UC_ARM_REG_R5
if reg == b'r6':
return UC_ARM_REG_R6
if reg == b'r1':
return UC_ARM_REG_R1
if reg == b'r3':
return UC_ARM_REG_R3
if reg == b'r4':
return UC_ARM_REG_R4
if reg == b'r0':
return UC_ARM_REG_R0
raise (Exception(reg))
def translate_regs_x86(reg):
if reg == b'ebx':
return UC_X86_REG_EBX
if reg == b'eax':
return UC_X86_REG_EAX
if reg == b'ecx':
return UC_X86_REG_ECX
if reg == b'edx':
return UC_X86_REG_EDX
raise (Exception(reg))
def dispatch(code: bytes, arch: bytes, regs: list):
if arch == b'AArch64':
regs = [translate_regs_arm64(r) for r in regs]
register_values = arm64_execute(code, regs)
return register_values
if arch == b'x64':
regs = [translate_regs_x64(r) for r in regs]
register_values = x64_execute(code, regs)
return register_values
if arch == b'x86':
regs = [translate_regs_x86(r) for r in regs]
register_values = x86_execute(code, regs)
return register_values
if arch == b'ARM32':
regs = [translate_regs_arm32(r) for r in regs]
register_values = arm32_execute(code, regs)
return register_values
raise (Exception(arch.decode()))
def handle_received(received):
question = get_question(received)
if question is not None:
code, arch, regs = parse(question)
code = to_bytes(code)
register_values = dispatch(code, arch, regs)
return register_values
def to_bytes(bb: bytes)->bytes:
res = []
if len(bb) % 4 != 0:
raise (Exception("invalid"))
for _ in range(len(bb)//4):
res.append(bytes.fromhex(bb[2:4].decode()))
bb = bb[4:]
return b"".join(res)
def reply(s: socket, reg_values: list[bytes]):
print(reg_values[0])
reply = f"0x{reg_values[0]:02x},0x{
reg_values[1]:02x},0x{reg_values[2]:02x}"
print(reply)
s.send(reply.encode()+b"\n")
pass
def main():
s = init()
received = s.recv(20_000)
response = handle_received(received)
while True:
received = s.recv(20_000)
if received == b'':
return
print(received)
response = handle_received(received)
print(response)
if response is None:
continue
reply(s, response)
# test_x64_bis()
# test_arm64()
# test_arm32()
# test_arm32_bis()
# test_x86()
# test_x64()
if __name__ == '__main__':
main()









