30/11/2016
Blog technique
An introduction of Use-After-Free detection in binary code by static analysis
Cédric Berthion, Dimitri Kirchner, Florent Saudel

Use-After-Free is a well-known class of vulnerabilities that is commonly used by modern exploits (cf. [Pwn2own](http://blog.trendmicro.com/pwn2own-day-1-recap/) [2016](http://blog.trendmicro.com/welcome-mobile-pwn2own-2016/)). In the research project [AnaStaSec](http://www.agence-nationale-recherche.fr/?Projet=ANR-14-CE28-0014), AMOSSYS works on how to statically detect such vulnerabilities in binary codes. In this blog post, we explain how the scientific community suggests detecting such type of vulnerabilities. The goal of this state of the art is to define a global methodology that will then let us build a proof of concept tool that satisfies our needs.

Use-after-Free (UAF) description
The principle of a UAF is pretty simple to understand. Use-After-Free vulnerabilities occur when a program tries to access a memory area which has previously been freed. In this case, what we call a dangling pointer is created and points to a freed object in memory.
To give an example, the code below will lead to a UAF. If this code is executed and if the error branch is taken, an undefined behavior is likely to occur since ptr points to a non-valid memory area.
`char * ptr = malloc(SIZE);
…
if (error){
free(ptr);
}
…
printf("%s", ptr);
Figure 1: Example of Use-After-Free
In other words, a UAF vulnerability appears when these 3 steps occur:
- A memory area is allocated and a pointer points to it.
- The memory area is freed but the pointer is still available.
- The pointer is used and accesses the memory area previously freed.
Most of the time, a UAF vulnerability can lead to a leak of information. But what is even more interesting is when UAF leads to code execution. This can be done in several steps:
- Program allocates and then later frees memory block A.
- Attacker allocates a memory block B, reusing the memory previously allocated to block A.
- Attacker writes data into block B.
- Program uses freed block A, accessing the data the attacker left there.
In C++, this is often done when a class A is freed and an attacker succeeds on allocating a class B on the memory area of A. Then, if a method a class A is called, the code loaded by the attacker in class B will be executed.
Now that we have clarified what a UAF is, let’s dig into how the community tries to detect such vulnerabilities.
Pros and cons of static and dynamic analyses
There are two main ways to analyze a binary: the static one and the dynamic one. Analyzing the whole code dynamically is today quite difficult, as there is no simple solution to generate inputs that will execute every paths of a binary. For this reason, static approaches seem more appropriate when one wants to focus on code coverage.
However, despite this observation, papers [Lee15] and [Cab12] explain that most academic works about Use-After-Free detection are focused on dynamic analyses. This is mostly because dynamic analyses let one easily check for copies of a same pointer, called aliases. In other words, when considering a dynamic approach, values in memory are directly accessible, and this is not negligible from an analysis point of view. When doing dynamic analyses, one will therefore gain accuracy but will also lose some completeness.
From our point of view, we however want to focus on static analysis. Two main difficulties are identified by the academic community:
- The biggest one is how to manage loops in programs. Indeed, when computing all possible values of handled variables in a loop, one needs to know how many times the loop will be executed. This issue is more generally known as the halting problem. In computability theory, the halting problem is to know whether the program will reach an end or continue to run forever. Unfortunately, this problem has been proved as an undecidable one. In other words, there is no generic algorithm to solve the halting problem for all possible programs with all possible inputs. In that context, static analysis tools are forced to do simplifications to resolve this issue.
- Another difficulty is the way of representing memory. A naive solution would be to keep a big array in which memory values of pointers are saved. However, this is not as simple as it seems. For example, a memory address may be filled with many possible values, or some variables may have many possible addresses. Moreover, if there are too many possible values, it is not reasonable to save every single value. As for the previous remark, some simplifications have to be done regarding this memory representation.
In order to reduce the complexity of static analysis, some papers like [Ye14] or tools like Polyspace or Frama-C work at the C source code level, since this level contains the maximum of information. However, one does not often have access to the source code of the application to analyze.
From binary to Intermediate Representation
If we focus on binary analysis, the first step is to build the associated control flow graph (CFG). A control flow graph is an oriented graph which presents all paths that might be traversed through a program during its execution. Each node of a CFG is an instruction. Two nodes linked by an edge represent two instructions which may be executed consecutively. A node with two edges to other nodes represents a conditional jump. Thus, building a CFG enables to organize the binary code into a logical sequence of instructions. A well-known way to build the CFG of an executable is to use the disassembler IDA Pro.
When working on binaries, academic papers always seem to process the same way regarding UAF vulnerabilities. Papers [Gol10] and [Fei14] detail these different steps:
- Facts seem to show that loops have no great influence on Use-After-Free presence. Therefore, unrolling loops keeping only the first iteration is a mandatory step to start working on the binary. Regarding what we just explained before, this step allows us to avoid the halting problem explained in 1).
- In order to facilitate problem number 2), an Intermediate Representation (IR) is built to have a representation which is independent of the processor’s architecture. As an example, x86 assembly code is too complex because it has too many instructions. A solution is therefore to perform an analysis on a smaller set of instructions. With an Intermediate Representation, each instruction is converted into several atomic instructions. The choice of one IR amongst another depends on the kind of analysis that one wants to perform. In most of the cases, Reverse Engineering Intermediate Language (REIL) is used, but BAP ([Bru11]) or Bincoa ([Bar11]) are other IRs used in academic works.
Only 17 different instructions compose the REIL IR and each instruction has at most one result value. The translation from native x86 assembly to REIL code may be provided by a tool like BinNavi, which is an open source project now developed by Google (and previously Zynamics). BinNavi can take as input an IDA Pro database file, which could be quite convenient.
Symbolic execution versus abstract interpretation
Once an Intermediate Representation has been built, two methods are today considered to analyze the binary’s behavior: abstract interpretation ([Gol10] and [Fei14]) or symbolic execution ([Ye14]).
Without being too specific, an analysis by symbolic execution follows the instruction set. Rather than obtaining actual value for inputs, symbolic execution uses symbols for expressions and variables in the program. Thus, the analysis does not track values of variables, but builds arithmetic expressions with symbols representing each value. These computed expressions can, for instance, be used to check conditional branches.
On the other part, abstraction interpretation is based on the idea that the analysis of a program can be done at some level of abstraction. Thus, there is no need to track the exact value of each variable. The semantic is replaced by an abstract semantic that allows to describe the impact of instructions on variables. For instance, variables may be defined by their sign. For an instruction of addition, the sign of operands will be checked to set the sign of the result. Thus, if the operands were +, the result would be +, but the exact value of variables will never be computed. It is possible to define many abstract domains other than the sign. For instance, it is possible to track values of variables through a value interval on a memory location (globals, heap and stack). A well-known analysis using this kind of representation is called Value Set Analysis (VSA).
As a concrete example, the framework monoREIL is a VSA engine which relies on the REIL IR. It simplifies VSA algorithm development to enable developers to perform VSA on their own abstract domains.
Analyzing the Intermediate Representation
The next issue is how to implement the analysis algorithm when browsing through the CFG. Once again, there is two ways of doing this:
- Intraprocedural analysis, which is limited to the scope of the current function,
- Interprocedural analysis, which has the ability to enter into subfunctions.
Needless to say, intraprocedural analyses are much simpler to implement than interprocedural’s. However, when one wants to detect UAF, he has to be able to follow memory chunks from their allocation to their freeing… and that is likely to happen in different functions.
That is why the paper [Gol10] proposes to first make intraprocedural analyses, and then to enlarge them to a global interprocedural analysis. This is showed on Figure 2. For each function, a block is created. These blocks sum up the behavior of functions and link their outputs with their inputs. Thus, when the analysis is enlarged to an interprocedural analysis, each function call is replaced by the results of the previous intraprocedural analysis of this function. The main pros of this method is that functions are analyzed only once, even if they are called many times. Moreover, intraprocedural analyses are performed on quite small code chunks, therefore they are quite precise.
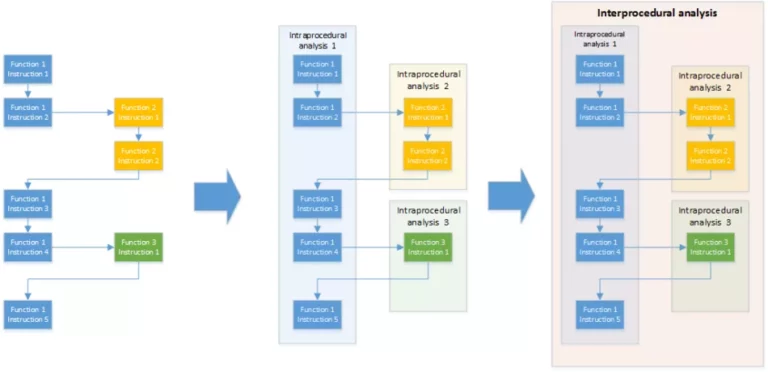
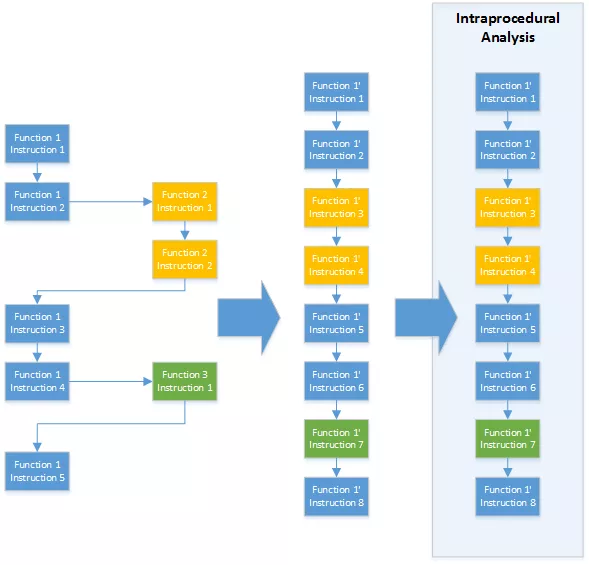
Another solution is presented in the paper [Fei14]. This second method (showed in Figure 3) consists in inlining callee functions into the caller function. Thus, function calls are no more an issue. This solution may be easier to implement but has the limitation that the function will be analyzed twice if it is called twice. Therefore this method is considered to be more time and memory consuming.
Detecting UAF
At this point, we have methods to analyze binary code semantics and methods to traverse the Control Flow Graph. What we now want to detect is UAF patterns. Let’s focus on the following definition: a UAF is characterized by an occurrence of two distinct events:
- The creation of a dangling pointer,
- An access to the memory pointed by this pointer.
In order to detect this pattern, the paper [Fei14] builds at each statement the set of freed memory heap areas and checks at each use of a pointer if it points to one of these freed areas.
To give a trivial example, let’s take the following pseudo-code. Note that, to simplify, this example does not present a complex CFG. Indeed, the way to deal with the CFG depends on the chosen analysis method and its implementation… The goal of this example is only to show a way to detect Use-After-Free once the code has been analyzed.
1. malloc(A);
2. malloc(B);
3. use(A);
4. free(A);
5. use(A);
This pseudo-code allocates two memory chunks referenced by the names A and B. Then, the memory chunk A is accessed (Use(A)) before being freed (Free(A)). After that, the memory chunk is accessed again.
By defining two domains (a set of allocated heap elements and a set of freed heap elements), it is possible to update these sets at each instruction and to check if accesses refer to chunks which belongs to the allocated memory chunk set. This is illustrated in Figure 4.

When the memory chunk A is accessed again, it had been registered as a freed memory chunk in the previous step, so the analysis can rise an alert: a Use-After-Free is detected.
Another way to detect the wanted pattern, described in [Ye14], is by using a simple state-machine. The idea is that after a malloc, pointers to chunks are set in an “allocated” state, and they stay in this state while they are not freed. When they are freed they pass to a “Freed” state. This state leads to a “Use-After-Free“ state if a pointer in a freed state is used. If however, a pointer and its aliases are deleted and do not refer to the memory chunk, then they are no more harmful and they can go to a “End“ state. This simple state-machine is showed in Figure 5.

Yet another solution, proposed by [Gol10], is to use graph theories. In this paper, the authors check if the statement which uses a pointer comes after or before the basic bloc which freed the memory. If it is after, they spotted a UAF vulnerability.
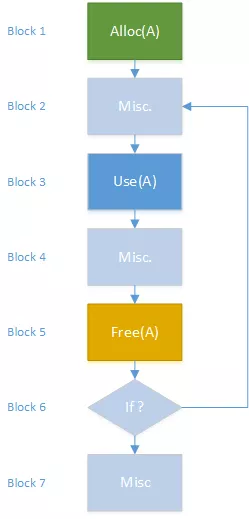
Figure 6: Graph with potential Use-After-Free
In all cases when a dangling pointer is detected, the last phase of the analysis has to characterize the UAF vulnerability by extracting the subgraph which leads to it. This subgraph has to contain all the elements needed to let a human person manually check in order to avoid true positives.
Final thoughts
We have presented here several ways to deal with Use-After-Free detection on binaries using static analysis methods. We have tried to explain the different problems that this kind of analyses triggers, and one can easily understand that there is no straightforward solution to detect this kind of bug.
What we have also seen during this work is that only a minority of researchers releases their work as open source projects. The project GUEB which is developed by Josselin Feist in the Verimag team is one of them. If you are intested in this subject (and not afraid of Ocaml code), we encourage you to checkout his Github.
To finish, the research project AnaStaSec is the opportunity for AMOSSYS to analyse current academic results on UAF detection with the goal to leverage and enhance existing tools. Even if this post is not releasing anything, we expect to do so in the next years. So stay tuned!
Bibliography
- [Lee15] Preventing Use-after-free with Dangling Pointers Nullification. Byoungyoung Lee, Chengyu Song, Yeongjin Jang, Tielei Wang. s.l. : NDSS Symposium 2015, 2015.
- [Cab12] Early Detection of Dangling Pointers in Use-after-Free and Double Free Vulnerabilities. Juan Cabaleero, Gustavo Grieco, Mark Marron, Antionia Nappa. IMDEA Software Institute, Madrid; Spain : ISSTA 2012, 2012.
- [Ye14] UAFChecker: Scalable Static Detection or Use-After-Free Vulnerabilities. Jiay Ye, Chao Zhang, Xinhui Han. s.l. : CCS’14, 2014.
- [Gol10] Gola, Vincenzo Iosso. Detecting aliased stale pointers via static analysis. s.l. : Politecnico di Milano, 2010.
- [Fei14] Statically detecting use after free on binary code. Josselin Feist, Laurent Mounier, Marie-Laure Potet. s.l. : Journal of Computer Virology and Hacking Techniques, 201
- [Bru11] Brumley, D., Jager, I., Avgerinos, T., Schwartz, E.J.: Bap: a binary analysis platform. In: Proceedings of the 23rd International Conference on Computer Aided Verification. CAV’11, pp. 463–469. Springer, Heidelberg (2011)
- [Bar11] Bardin, S., Herrmann, P., Leroux, J., Ly, O., Tabary, R.,Vincent, A.:The bincoa framework for binary code analysis. In: Proceedings of CAV’11, pp. 165–170. Springer, Berlin (2011)









