12/08/2020
Blog technique
Spectre V1 in userland
Emile Josso

Introduction
In early 2018, the Spectre & Meltdown flaws [1][2] started to dig a hole in CPU security, removing the first brick of a fortress long thought untakable. Ever since, a lot of papers have been published, showing that more and more parts of processors are flawed. CPU vendors and OS developpers have been issuing microcode/software patches to plug the leaks, with a certain success, in the expense of performance. But most of the patches have been deployed in OS/compilers, and not in userland-running software themselves, even though some of them (especially system-available daemons such as sshd) contain highly sensitive information.
This blogpost focuses on the impact of the Spectre V1 vulnerability on userland programs, based on a simple cross-address-space proof of concept. We will explain how an attacker may be able to exploit perfectly normal code-flow in a program in order to leak sensitive information and then tackle with ways to prevent any Spectre flaw in userland software.
Overview
Before dealing with the attack, we must first give a small recap on how modern speculative execution work. Do not worry, we will make it short !

Caches
Caches are small pieces of memory, close to the CPU, that store recent or frequently issued memory load/store. As their access time (~4-80 CPU cycles) is really smaller than the DRAM access time (~200-400 CPU cycles), caches really speed up execution time. Caches are typically organized in a multi-level, inclusive hierarchy: smaller caches have lower access time, whereas bigger caches include data stored in lower levels and have higher access time. On desktop/server Intel architectures, three levels of caches are present: L1 & L2, that are shared along a physical core; and the L3 (or LLC), shared amongst all cores.
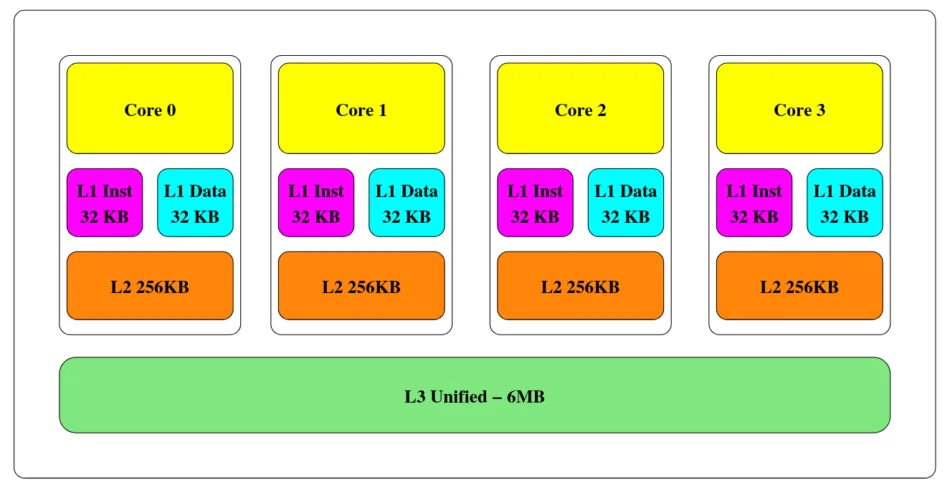
Cache hierarchy of Intel Ivy Bridge. Source: see note [2] at the bottom of this blogpost
Whenever the CPU needs to read a data from memory, it will first check if the data is not in any of its caches levels, and then issue a read request from the DRAM. Whenever the data arrives, its is put in cache in order to make following reads quicker.
Remark: on a x64 platform, you can disable CPU caches by setting the CD bit in the cr0 control register.
Speculative execution
Speculative execution is a way to furthermore increase performance in CPUs. Most of the speculative execution techniques try to remember the behaviour of a program in order to predict what will be the next instruction to execute or the next memory location to read. The Spectre flaw abuses one of its mechanisms, called the Pattern History Table (PHT). The PHT remembers the behaviour of conditional branches and speculates on the outcome of a branch: suppose that you have an if() condition that is true 100 times, then the PHT will remember this branch as « really taken » and, when asked, will tell that this branch will really likely be taken a 101th time.
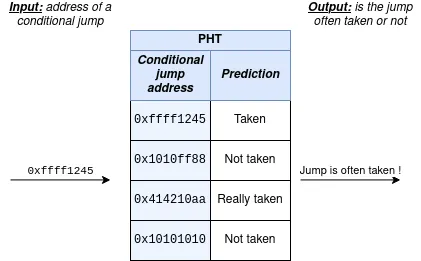
A simplified view of the Pattern History Table
What is its purpose ? Actually, an if() condition can take time (from a CPU cycles perspective) to be resolved: maybe one of the operands used to resolve the conditon is not in cache. In that case, the CPU will not wait for the operand to come from the DRAM. Instead, the CPU will speculate on the outcome of the branch, using the PHT to know wether to take the branch or not. By speculating, the CPU will start to execute instructions transiently, meaning that the executed instructions will not be visible but every change will be stored in an internal buffer. Once the outcome of the branch is resolved, the CPU can check if the instruction path it executed was the correct one: – if yes, then architecural changes done by the speculative execution are made visible; – if no, the internal buffer used to store speculative changes is flushed, and the other path is taken.
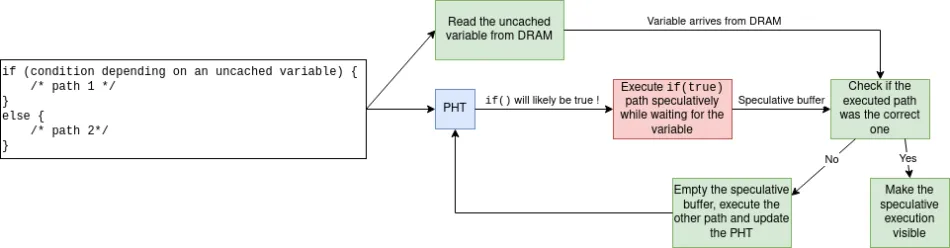
How the PHT is used to make a prediction about a condition
Spectre V1
The Spectre flaw abuses the fact that in case of a speculative execution misprediction, cache changes made during the speculative execution are not undone, and are visible from an user perspective. The main idea of the attack is to:
Make the victim train some microarchitectural element to predict a certain path.
Give one input that is invalid but, because of the training, will be predicted as valid.
Retrieve information leaked by the invalid speculative execution.
The third point can be done in a various number of ways, but for the sake of simplicity we will focus on the Flush+Reload side-channel attack explained below.
Flush+Reload
Flush+Reload 3 is a LLC cache-leakage technique, based on timing difference between a data present in cache and a data not in there. A high level overview follows:
- Identify a shared memory zone with the victim, that the attacker wants to know if the victim accessed or not.
- (Flush): Use the x64
clflushinstruction to remove the memory zone from every level of the cache hierarchy. - Wait for the victim to execute code manipulating the shared memory zone.
- (Reload): Access the memory zone. If the access time is low, then the data was found in cache, meaning that the victim accessed the memory zone.

Overview of the Flush+Reload technique. (A) describes a situation where the victim does not access the shared memory, (B) describes an access. Both lines represent time. In scenario (A), the victim does not access the shared memory zone, so the reload time of the attacker is long. In scenario (B), the victim performs an access, implying the reload time of the attacker is short. Is is thus able to detect that the victim accessed the shared memory zone. Source: see note [2] at the bottom of this blogpost
This technique is really useful for cross-core cache attacks (e.g. attacks on virtually hosted environments) because of its reliabiltiy, simplicity and accuracy.
Spectre V1: basics
Now that everyting is set up, we can finally deal with the attack. To make things clear, we will focus on the following code sample:
char array1[16] = {0,1,2,3,4,5,6,7,8,9,1,0,11,12,13,14,15};
char probe_array[256];
size_t array1_size = 16;
/* secret may be determined at execution time, we put it here
* as a constant string for improved readibility */
static char* secret = "Hello there ! General Kenobi !�";
/* ... */
char vulnerable_function(size_t x) {
if (x < array1_size) {
return probe_array[array1[x]];
}
return 0;
}
Imagine a situation where the attacker can input any x to vulnerable_function(). The attacker wants to get the bytes stored at the address pointed by secret. The steps of the attack follows:
Give many
xas input ofvulnerable_function()such thatxis strictly inferior thanarray1_size. This will train the PHT to tell that theif()is often taken.Flush
array1_sizefrom the cache hierarchy. This will force the CPU to rely on the PHT the next time it will encounter theif(). Also flushprobe_arrayfrom the cache hierarchy.Input an
x_roguesuch thatarray1 + x_rogue == secret. As the CPU will speculate, this will accessprobe_array[secret[0]]transiently, thus putting a specific index ofprobe_arrayin cache (between 0 and 256). This index depends entirely on the valuesecret[0].Iterate over every indexes of
probe_array, and measure access time to each one of them. Since one and only one index has been accessed speculatively, the index with the smallest access time is the value ofsecret[0].
Depending on the context this attack is performed, there are additionnal subtleties that are required to be dealt with.
Additionally, we did not tackle with the size of the zone used to leak bytes read by the attack (here, probe_array). Ideally, this zone must be pretty big, as the clflush instruction actually flushes a whole cache line (typically 64 bytes), so there must be some spacing in probe_array. To show this required spacing, we could have declared the array as char probe_array[256 * 4096].
Code process
Important note: As Spectre flaws rely on the underlining microarchitecture, it is pretty hard to make any assumptions about why a certain attack will work or not. Caches organization, speculative engines, … can highly vary between architectures, and we experimentally found that attacks working on a certain architecture didn’t work on another computer. For the curious, a good starting point to gather information about your CPU architecture may be this site, as it summarizes information about a whole bunch of CPU families and architectures.
In a Spectre V1 cross-process scenario, we assume the attacker to be unprivileged but he can execute any code he wants on the machine (for instance, he pwned a website and gained access to a bash interpreter on a victim machine). The attacker wants to leak information from another process, e.g. SSH keys from an SSH server.
To leak information, the attacker has to send some specifically crafted inputs to its target (for instance to the SSH daemon), that will be forwarded to a Spectre-vulnerable function.
In order to fully understand the inner workings of a Spectre V1 cross-address-space unprivileged attack, we coded a small proof of concept that is publicly available and freely shareable and modifiable.
The first question to ask is: « What side-channel should the attacker use to retrieve leaked information ? ». As Flush+Reload is an easy-to-use, efficient technique, we will focus on this one, but one could use other such as Prime+Probe on the LLC [4] or a subtle timing attack [5].
We suppose that the attacker is able to read the target executable on disk (i.e: the compiled binary of a sshd server in /usr/bin/sshd), and that he identified in the victim’s binary an exploitable Spectre flaw.
The first thing the attacker must do is to map (via mmap() for instance) the victim binary in its own address space. The attacker will then share every read-only pages with the victim, as well as every not dirty pages.
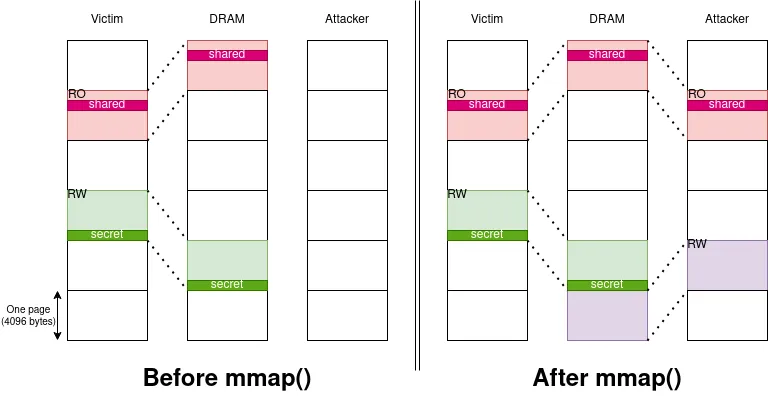
After an mmap(), the attacker shares read-only/not dirty pages with the victim
The attacker must then locate in the victim binary two memory locations:
- The offset in the file of the operand used to perform the Spectre condition in order to flush it. In our example above, this would be the offset of
array1_size. This is used to force the CPU to rely on the PHT, as he has to fetch the operand from DRAM before resolving it. The attacker could also use other cache-manipulation techniques, such as Prime+Probe on the LLC [4]. - The offset in the file of a read-only/undirty memory location used to leak the read bytes in a Spectre attack. In our example above, this would be the offset of
probe_array.
Note: Those requirements are here only because we consider a Spectre attack based on the Flush+Reload technique. By using another technique, one could find another ways to retrieve leaked information (sparing the use of probe_array) and to force the CPU to rely on the PHT (sparing the use of array1_size).
Once done, the attacker can compute the virtual addresses where both memory locations are located in its own address space, simply by adding the offsets to the address the binary has been mapped to. He now knows that those two addresses are physically shared with the target.
He then flushes the memory location used to leak bytes from the cache hierarchy. As the leakage will be performed in this zone, it is important to keep it clean in order to avoid false positives.
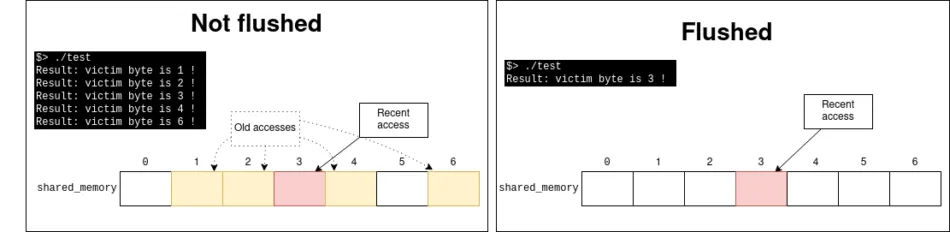
Unflushed shared memory location causes false positives in the attack
Then, he starts sending valid inputs to the server, thus training the PHT on correct values. Before sending the rogue input, he must flush from the cache hierarchy the value used to compute the Spectre-vulnerable conditional jump that will trigger the information leak. Otherwise, the value has high chances to be in cache and the CPU will not do speculative execution on the target condition.
The attacker can then send a rogue input, that will trigger the Spectre attack, speculatively reading the secret and storing it in cache.
Finally, to retrieve the secret byte, he just has to measure access time to the shared memory location. The index with the smallest access time depends on the read value of the secret
Note about cross-core: As on Intel platforms caches are inclusive, this means that any value stored in the L1 cache is also stored in the LLC. This attack can then work if the attacker and the victim are not located on the same physical core, as the LLC cache level is shared amongst all cores, the attacker will still be able to know if the victim accessed a shared memory location or not. Practically, we found this obersvation to be untrue, as on some machines the attack worked, whereas on others not due to too much noise.
The figure below resumes a cross-core Spectre V1 attack using the Flush+Reload technique. Step (a) show the training of the victim program by sending correct input. In step (b), the attacker sends invalid input that will trigger a speculative out-of-bounds read. Finally, in step (c), the attacker analyzes the cache to find the leaked value.
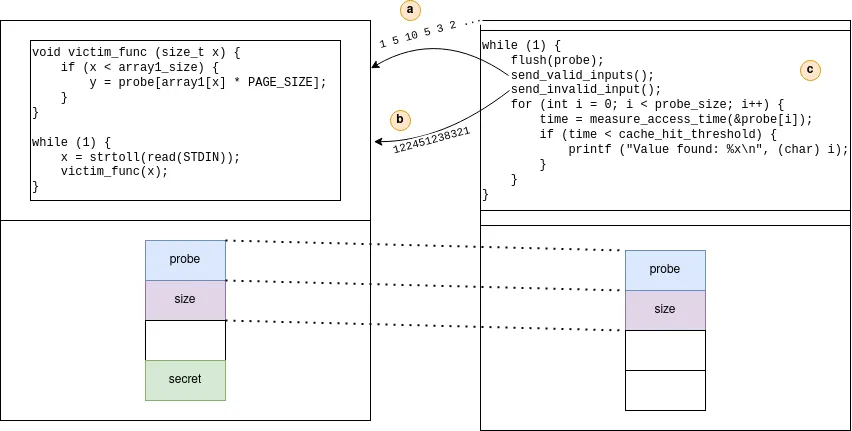
Overview of the Spectre V1 cross-address-space attack. Left: Victim, Right: Attacker
The main difficulty of this attack is to find a Spectre-vulnerable gadget. Experimentally, we analyzed various libraries with custom tools and found that a lot of code chunks that could be vulnerable missed some condition to be really exploitable using the Flush+Reload technique: for instance, we found a lot of patterns that perfomed the leakage on a R/W memory location, thus blocking the attacker from reading any leaked value. Even though this prerequisite could be bypassed using the Prime+Probe on the LLC technique, it significantly increases the difficulty of the attack and we did not dig it enough to perform an actual exploit.
Available protections
For two years, a lot of different countermeasures have been proposed against the Spectre attack: from hardware protections using CPU microcode updates (like IBRS/IBPB [6]), to software countermeasures both in user-space (like V8’s index poisonning [7]) to kernel-space (whose patches basically stops speculation in critical code). In order to protect software/libraries, one can use any hardware solution (but the developer may not have access to this kind of tweakings on the machine its softwarte runs), or use any mainstream solution implemented in compilers. Basically, they adopted two countermeasures for a widespread use:
- lfence
- index masking
lfence
On x86 CPUs, this intruction acts as a LOAD fence, meaning that the processor will wait for any issued memory read prior to the lfence instruction to successfully being fetched from DRAM before continuing code execution. As a side effect, this instruction stops the speculative execution of a program. In an example like below:
if (x < array1_size) {
asm ("lfencen":::);
char y = array2[array1[x] * 4096];
}
the if() conditions issues a load to fetch array1_size from DRAM. The presence of the lfence instructions forces the CPU to wait for array1_size from DRAM, meaning that the Spectre flaw can no longer be effective.
The main issue with this countermeasure is its performance loss, as thousands of execution are speculatively executed each second, seriously increasing the performance of a CPU.
Index masking / Speculative load hardening
This technique applies a bitmap that nullifies a memory load when the CPU is speculating. The following code shows its implementation, using the example located above in this blogpost:
void patched_function (size_t x)
{
int* addr;
predicate_state = 0xffffffffffffffff;
if (x < array1_size) {
predicate_state =
!(x < array1_size)
? 0x0
: predicate_state;
addr = probe_array + array1[x];
addr &= predicate_state;
return *addr;
}
}
When speculating, the CPU will say that the condition x < array1_size is true, thus setting predicate_state to 0. By applying an & mask, the accessed address will always be 0x0, thus avoiding the leakage during speculation.
From a performance perspective, this countermeasure is way less costly than lfence but still implies a little overhead. For more information see here.
Recap
The following table resumes which protection is available in mainstream compilers, and which CLI option enables them:
As we can see, GCC does not currently implement any automatic Spectre V1 detection/prevention (even though it can prevent Spectre V2).
MSVC can protect binaries against Spectre V1, but at a performance cost as it only uses the lfence instruction. We found that the detection algorithm it uses was greedy, meaning that it applies countermeasure in places where it could have not be required.
Clang, on the other hand, provides both type of protections. Once again, their countermeasure is really greedy, as it sanitizes any load instruction, implying a performance tradeoff.
System checkers
Additionnaly, some tools have been built to check if your CPU/OS is vulnerable to the Spectre flaw.
On Linux, one can use the spectre-meltdown-checker script to detect not only if their system is vulnerable to Spectre V1, but also to more recent microarchitectural attacks. This script provides an overview of the CPU microcode updates, and also checks for countermeasures in the Linux kernel.
On Windows, there is the inspectre tool that allows the user to check if their kernel is patched against Spectre/Meltdown flaws.
Important note: If your OS is told not vulnerable to the Spectre attack, this does not mean that your userspace softwares are not vulnerable ! Patches have been issued in the kernel that stop speculative execution during user/kernel context switch, but this does not have any effect on userland programs.
Conclusion
Even though a Spectre V1 cross-address-space PoC is not so hard to build, real-life attacks are much more of a pain. One must perfectly understand their target’s CPU and the behaviour of their target’s binary to be able to build such an attack. Even though, some realist proof of concepts have been made, especially a spectacular one targeting the windows kernel [8], and reading arbitrary memory from it. We can only recommend a developer to watch for those flaws, especially when building a secure component of a system.
Since the original release of the Spectre paper, a plethora of new attacks have been unrevealed by researchers. From Foreshadow that allows an attacker to read arbitrary host memory in a VM, to the recent Load Value Injection that virtually targets ANY load performed by a program, new microarchitecural flaws are disclosed every month and will surely continue to be disclosed until computer architects manage to build secure processors that take into account side-channels caused by their optimizations.
One can find a good resume of recent attacks on this website.
References
- Spectre paper
- Meltdown paper FLUSH+RELOAD: a High Resolution, Low Noise,L3 Cache Side-Channel Attack, Yuval Yarom and Katrina Falkner, 2013
- Last-Level Cache Side-Channel Attacks are Practical, Fangfei Lieu and Yuval Yarom and Ge Qian and Gernot Heiser and Ruby B. Lee, 2015
- NetSpectre: Read Arbitrary Memory over Network, Michael Schwarz and Moritz Lipp and Martin Schwarzl and Daniel Gruss, 2018
- Intel Deep Dive: Indirect Branch Restricted Speculation link
- A year with Spectre – a V8 perspective link
- Bypassing KPTI using the Speculative Behaviour of the SWAPGS instruction, Andrei Lutas and Dan Lutas link









